I find machine's working automatically to complete a task one of the most fascinating things, imagine how good it feels to watch a machine that learns to do the task on it's own! Especially if you're the teacher, in this blog post, we're going to go through:
- How to set up an environment in Unity
- How to interface with ML Agents to train an agent to complete a task
- Watch our trained model complete the task
Before we dive into anything technical, let's see something I prepared earlier!
Setup ML Agents and Unity Environment
See my previous post on how to set up ML Agents (on an apple silicon mac) here: [INSERT LINK TO POST]
Setup Environment
The goal that we will set for our agent to complete will be to roll towards a reward until it touches it. To do that we will need:
- A character for our agent to control
- Movement controls for our agent
- Boundaries for our agent to stay within (floor, walls, etc)
- The reward for our agent to touch
Character
Keeping things simple, we will create our agent to be a sphere with 2 eyes (with no collision), to add some flavour to our character.

Movement
To give the ability for our agent to control the character, we will attach a script to the character. This can be achieved through selecting the sphere > add component > new script
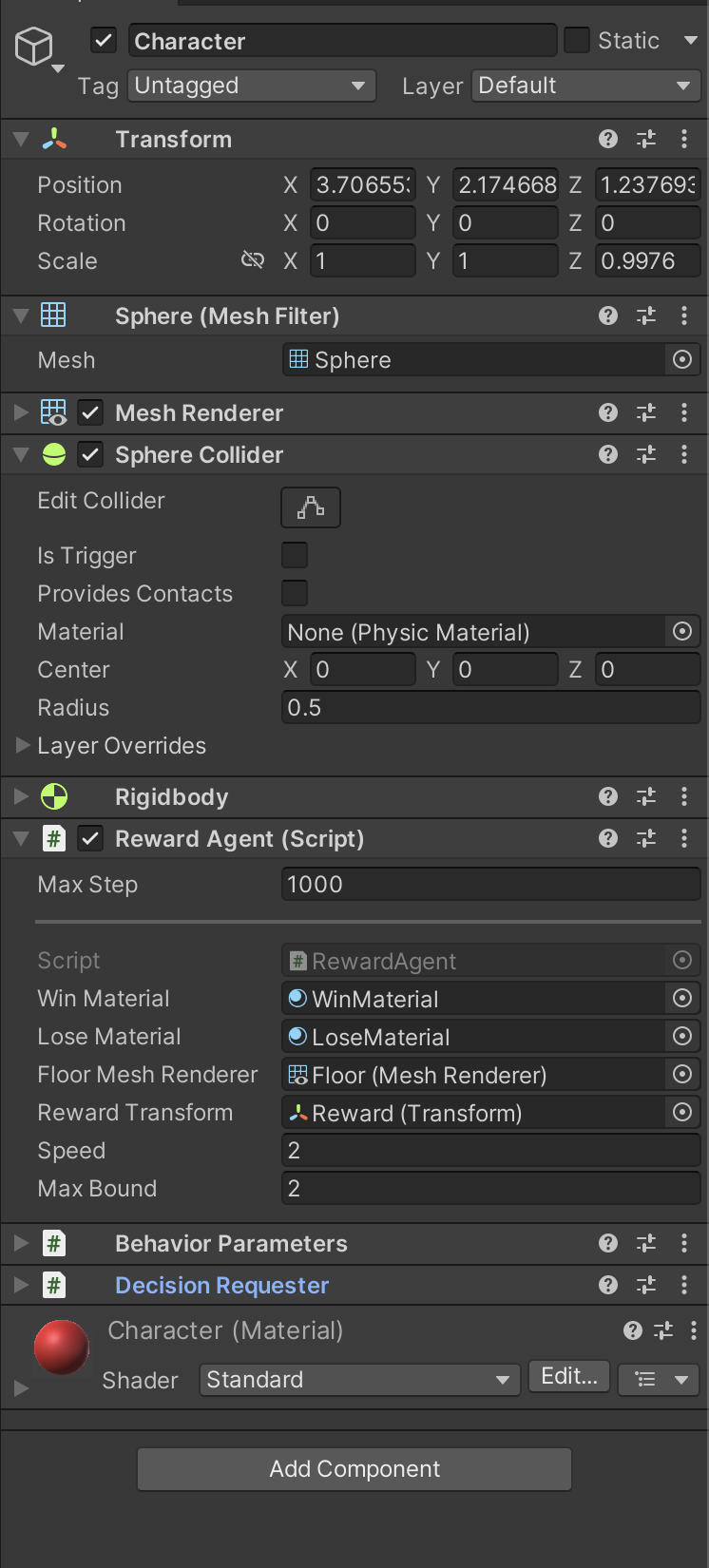
Inside the script, we will use Unity's addForce to give us the movement, and we will make use of MLAgents' heuristics such that we can toggle between agent controlled movement and controlled by us. If you leave this setting to default, it'll automatically choose for you.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35 | using Unity.MLAgents;
using Unity.MLAgents.Actuators;
using Unity.MLAgents.Sensors;
using UnityEngine;
public class RewardAgent : Agent
{
public override void OnActionReceived(ActionBuffers actions)
{
// // Calculate movement direction
Vector3 movementDirection = new Vector3(
actions.ContinuousActions[0],
0f,
actions.ContinuousActions[1]
).normalized;
// If there is movement input, apply force to move the sphere
if (movementDirection != Vector3.zero)
{
// Rotate the movement direction relative to the global coordinate system
movementDirection =
Quaternion.Euler(0, Camera.main.transform.eulerAngles.y, 0) * movementDirection;
// Apply force to move the sphere
agentRigidBody.AddForce(movementDirection * speed, ForceMode.Acceleration);
}
}
public override void Heuristic(in ActionBuffers actionsOut)
{
ActionSegment<float> continuousActions = actionsOut.ContinuousActions;
continuousActions[0] = Input.GetAxisRaw("Horizontal");
continuousActions[1] = Input.GetAxisRaw("Vertical");
}
}
|
Boundaries
Once you've created the desired environment for our agent to move in, create a prefab by nesting all of your game objects underneath a common parent (named Environment) and drag it into your project directory. This will enable us to copy and paste our prefab as many times as we want to train at scale. The walls transparent as they are distracting when there's lots of agents on the screen.
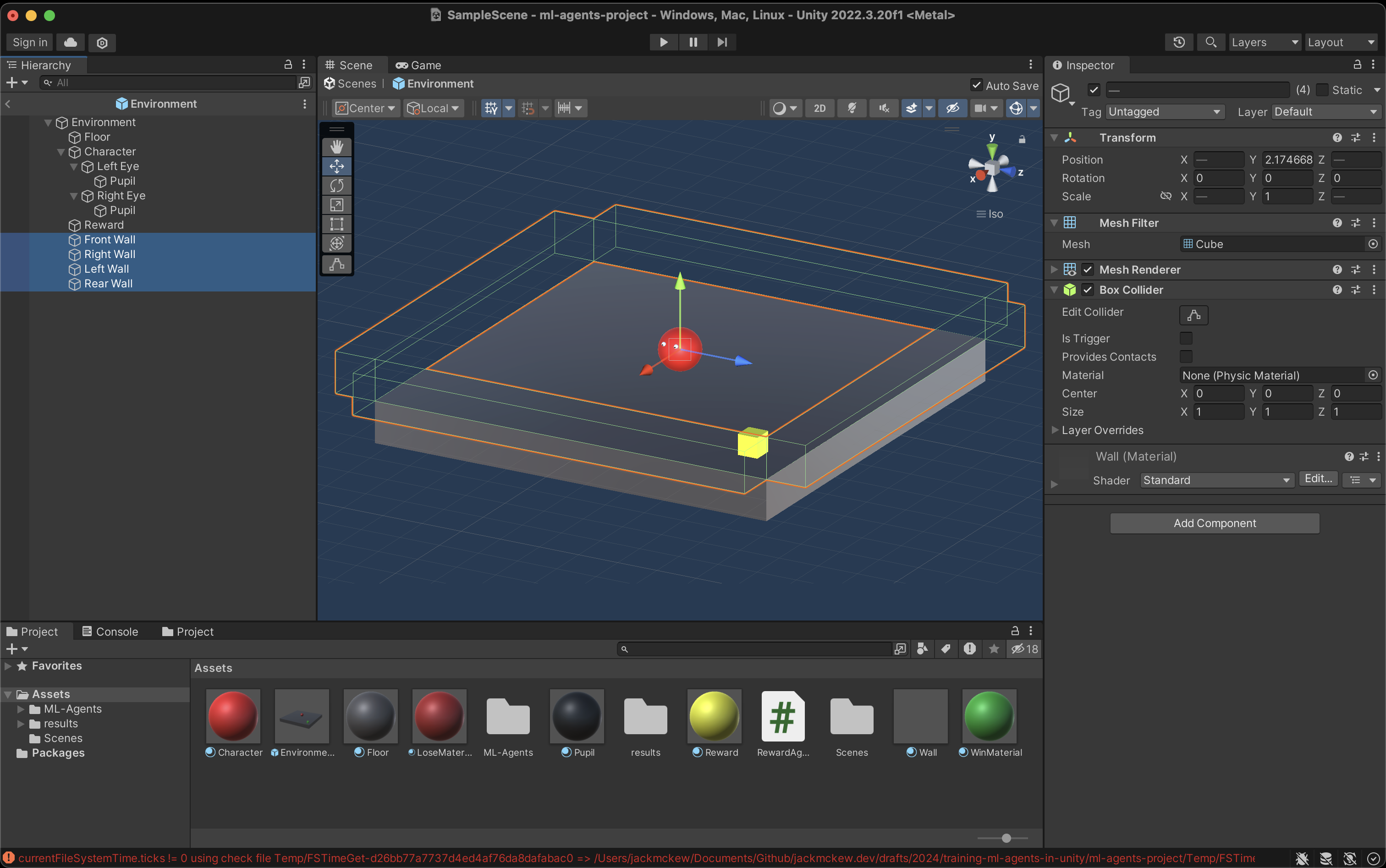
Ensure to use local position in your scripts if you are using a prefab otherwise it'll try to use the global position and strange things will happen
Integrate ML Agents
To integrate MLAgents we need to provide a few things:
- AddObservation to give our agent information about it's world
- AddReward when our agents do good (positive)/bad (negative)
- EndEpisode when our agent has either completed or failed the task
AddObservation
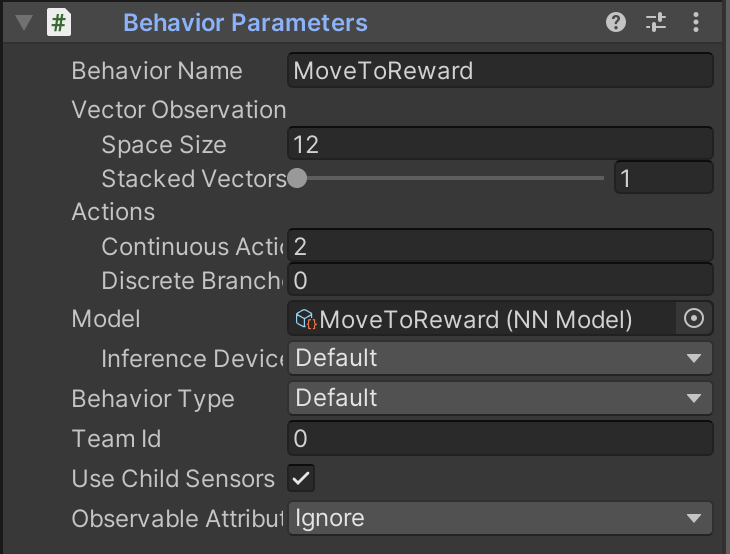
Overriding the public function of CollectionObservations enables us to give the agent the input to it's neural network. Ensure to set the Vector Space size correctly, in our scenario we have a space of 12, as we are passing through 4 vectors comprising of 3 elements (x, y, z).
| public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(transform.localPosition);
sensor.AddObservation(rewardTransform.localPosition);
sensor.AddObservation(agentRigidBody.velocity);
sensor.AddObservation(agentRigidBody.angularVelocity);
}
|
AddReward
Since our task is whether the character has either collided with the reward (success) or with the wall (failure), we set the collision function on our character to respectively AddReward and EndEpisode for our two outcomes. This will tell the model when it's training to reset the state of the environment, and for our sake, we'll colour the floor to whether they've succeeded or failed as well.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | void OnCollisionEnter(Collision collision)
{
if (collision.gameObject.name.Contains("Reward"))
{
AddReward(10f);
ResetRewardPosition();
floorMeshRenderer.material = winMaterial;
EndEpisode();
}
if (collision.gameObject.name.Contains("Wall"))
{
AddReward(-1f);
floorMeshRenderer.material = loseMaterial;
ResetAgentPosition();
EndEpisode();
}
}
|
The full script can be found within details:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157 | using Unity.MLAgents;
using Unity.MLAgents.Actuators;
using Unity.MLAgents.Sensors;
using UnityEngine;
public class RewardAgent : Agent
{
public override void OnActionReceived(ActionBuffers actions)
{
// // Calculate movement direction
Vector3 movementDirection = new Vector3(
actions.ContinuousActions[0],
0f,
actions.ContinuousActions[1]
).normalized;
// If there is movement input, apply force to move the sphere
if (movementDirection != Vector3.zero)
{
// Rotate the movement direction relative to the global coordinate system
movementDirection =
Quaternion.Euler(0, Camera.main.transform.eulerAngles.y, 0) * movementDirection;
// Apply force to move the sphere
agentRigidBody.AddForce(movementDirection * speed, ForceMode.Acceleration);
// Rotate the sphere to face the movement direction
// transform.rotation = Quaternion.LookRotation(movementDirection);
}
AddReward(-1 * (StepCount / 1000));
}
public override void Heuristic(in ActionBuffers actionsOut)
{
ActionSegment<float> continuousActions = actionsOut.ContinuousActions;
continuousActions[0] = Input.GetAxisRaw("Horizontal");
continuousActions[1] = Input.GetAxisRaw("Vertical");
}
[SerializeField]
private Material winMaterial;
[SerializeField]
private Material loseMaterial;
[SerializeField]
private MeshRenderer floorMeshRenderer;
[SerializeField]
private Transform rewardTransform;
public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(transform.localPosition);
sensor.AddObservation(rewardTransform.localPosition);
sensor.AddObservation(agentRigidBody.velocity);
sensor.AddObservation(agentRigidBody.angularVelocity);
}
public float speed = 10f; // Speed of sphere movement
private Rigidbody agentRigidBody;
void Start()
{
// Get the Rigidbody component
agentRigidBody = GetComponent<Rigidbody>();
ResetRewardPosition();
}
void ResetAgentPosition()
{
// Reset the force on the object
agentRigidBody.velocity = Vector3.zero;
agentRigidBody.angularVelocity = Vector3.zero;
transform.localPosition = new Vector3(1, rewardTransform.transform.localPosition.y, 1);
}
// These are recorded in localPosition
private Vector3 minBounds = new Vector3(-0.5f, 0f, -3f);
private Vector3 maxBounds = new Vector3(8f, 0f, 5.5f);
private float minDistance = 1f;
private Vector3 GenerateRandomPosition()
{
return new Vector3(
Random.Range(minBounds.x, maxBounds.x),
0f,
Random.Range(minBounds.z, maxBounds.z)
);
}
private bool IsPositionValid(Vector3 position, Vector3 referencePosition)
{
return Vector3.Distance(position, referencePosition) >= minDistance;
}
public Vector3 GetRandomPosition(Vector3 referencePosition)
{
int maxAttempts = 100;
int attempts = 0;
do
{
Vector3 randomPosition = GenerateRandomPosition();
if (IsPositionValid(randomPosition, referencePosition))
{
return randomPosition;
}
attempts++;
} while (attempts < maxAttempts);
Debug.LogWarning(
"Failed to find a valid random position within bounds after "
+ maxAttempts
+ " attempts."
);
return Vector3.zero; // Return zero if failed to find a valid position
}
void ResetRewardPosition()
{
Vector3 randomPosition = GetRandomPosition(transform.localPosition);
randomPosition.y = transform.localPosition.y;
rewardTransform.localPosition = randomPosition;
}
public float maxBound = 3f; // Maximum bounds for random position
private float episodeStartTime;
private float timePenaltyMultiplier = 0.1f; // Adjust this multiplier as needed
public override void OnEpisodeBegin()
{
// Reset any necessary variables at the beginning of each episode
episodeStartTime = Time.time;
}
void OnCollisionEnter(Collision collision)
{
if (collision.gameObject.name.Contains("Reward"))
{
AddReward(10f);
ResetRewardPosition();
floorMeshRenderer.material = winMaterial;
EndEpisode();
}
if (collision.gameObject.name.Contains("Wall"))
{
AddReward(-1f);
floorMeshRenderer.material = loseMaterial;
ResetAgentPosition();
EndEpisode();
}
}
}
|
Train
Training our model is quite straight forward with MLAgents, run in your python virtual environment ml-agents-learn and then heading back to Unity's Editor and pressing the Play button.
Adding --force will overwrite any existing training
Adding --run-id will give your run's a specific ID which is handy
Since we created a prefab, we can copy and paste our prefab as many times as we want to train in parallel.
Quirks
In an earlier attempt, I'd left the agent always starting in the same place, and the reward would always reset position. After training the model, the model decided the most optimal way of this task, was to run into the wall constantly in hope's that the reward would reset close enough. This is the life of reinforcement learning.

Run Trained Model
To show off our model once it's complete, for clarity sake we 'disable' the remainder of our prefabs (even though they will run in the background) and we drag our model's .onnx file into our character's Behaviour Parameters > Model, this will instruct the editor to use this for our character's brain.